

Google DeepMind Unveils Gemma 4 12B: A Multimodal AI Model for PCs
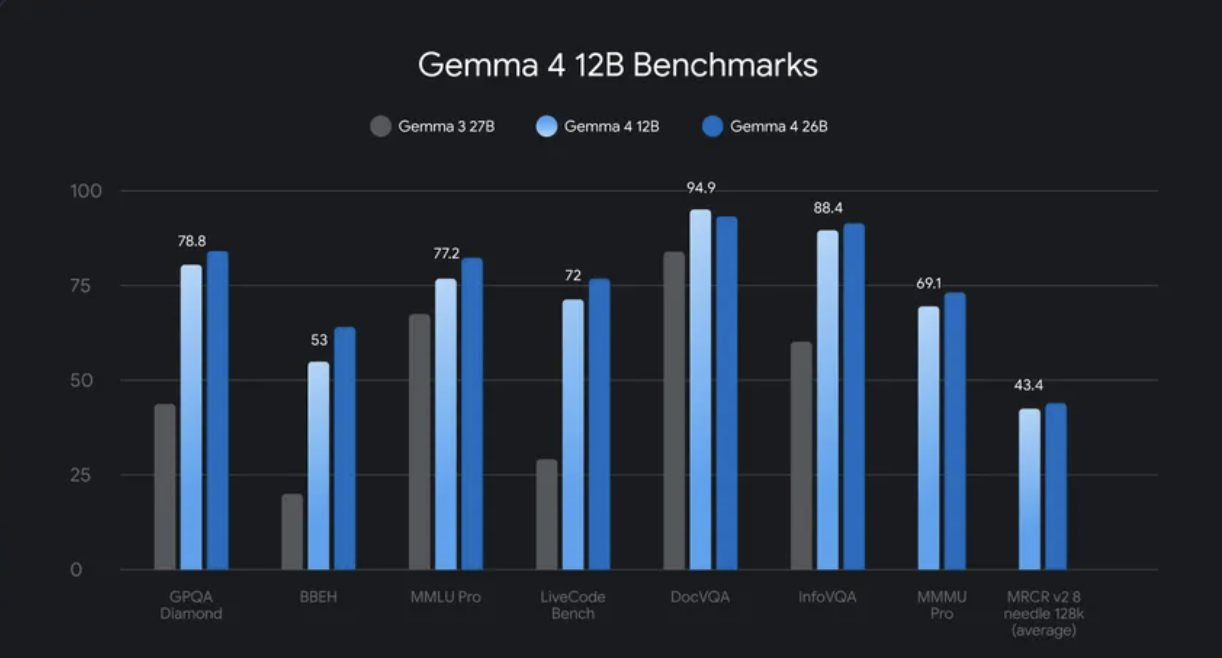
Google DeepMind has made a bold move with Gemma 4 12B, an innovative multimodal model that ditches traditional encoders entirely. This 12-billion-parameter model natively handles text, images, audio, and video—all while running on a standard PC with just 16GB of RAM. A first for a model of this scale, it represents a major leap in making advanced AI more accessible.
A Redesigned Architecture for Smoother Performance
Unlike previous versions of Gemma, Gemma 4 12B adopts an encoder-free structure, where visual and audio data are directly projected into the model’s latent space. This approach slashes latency and optimizes memory usage. For images, each pixel is divided into 48×48 patches, processed independently before being fed into the model. For audio, waveforms are segmented into 40ms frames, linearly projected to align with text tokens.
Open Ecosystem and Broad Accessibility
Released under the Apache 2.0 license, Gemma 4 12B is available as open source on Hugging Face and Kaggle. It’s compatible with tools like llama.cpp, MLX, and Ollama, and even supports Macs with Apple Silicon. A specialized instruct variant is offered for guided generation tasks. Google DeepMind also introduces a Multi-Token Prediction model to speed up local inferences.
A groundbreaking step toward democratizing multimodal AI—without sacrificing performance.