

Gemma 4 12B : un modèle IA multimodal sans encodeur pour PC
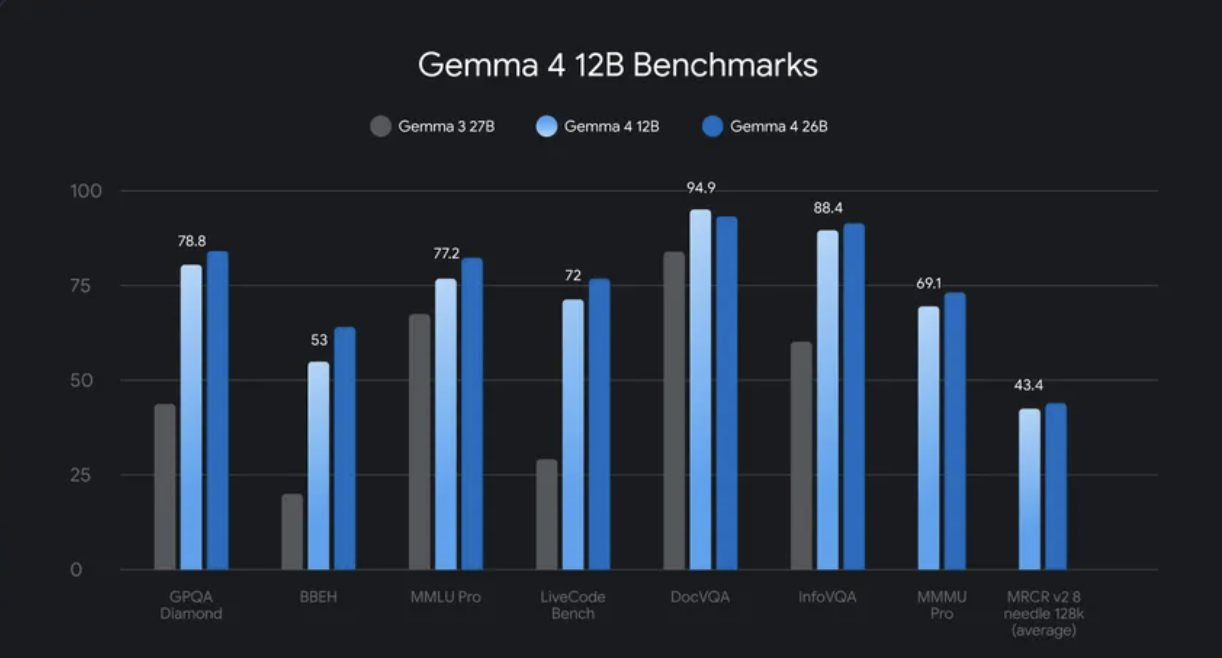
Google DeepMind frappe fort avec Gemma 4 12B, un modèle multimodal innovant qui abandonne les encodeurs traditionnels. Ce modèle de 12 milliards de paramètres gère nativement texte, images, audio et vidéo, tout en tournant sur un simple PC équipé de 16 Go de RAM. Une première pour un modèle de cette taille, qui marque un tournant dans l'accessibilité de l'IA avancée.
Une architecture repensée pour plus de fluidité
Contrairement aux versions précédentes de Gemma, Gemma 4 12B utilise une structure encoder-free, où les données visuelles et audio sont directement projetées dans l'espace latent du modèle. Résultat : une latence réduite et une consommation mémoire optimisée. Pour les images, chaque pixel est découpé en patchs de 48×48, traités indépendamment avant d'être injectés dans le modèle. Côté audio, les ondes sont segmentées en trames de 40 ms, linéairement projetées pour s'aligner sur les tokens textuels.
Accessibilité et écosystème ouvert
Publié sous licence Apache 2.0, Gemma 4 12B est disponible en open source sur Hugging Face et Kaggle. Il est compatible avec des outils comme llama.cpp, MLX ou Ollama, et supporte même les Macs sous Apple Silicon. Un variant instruct est également proposé pour des tâches de génération guidée. Google DeepMind y ajoute même un modèle de Multi-Token Prediction pour accélérer les inférences locales.
Un pas de géant pour démocratiser l'IA multimodale, sans compromis sur la performance.
Source : MarkTechPost. Synthèse éditoriale assistée par IA — TechnoExpress.